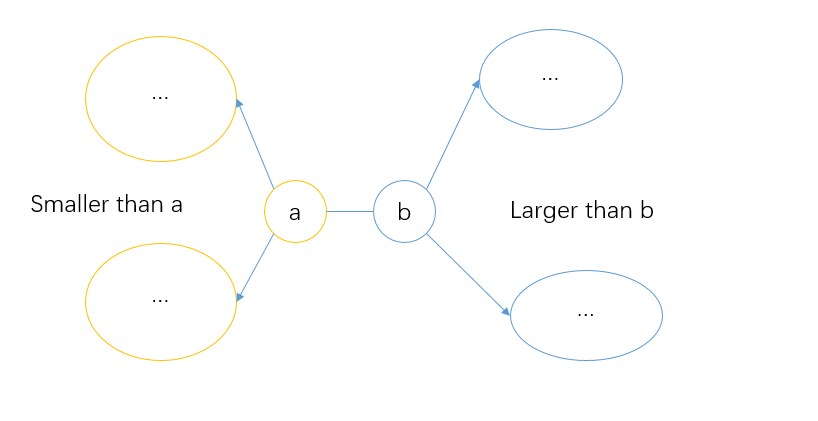
classKthLargest{public:priority_queue<int,vector<int>,greater<int>>larger;priority_queue<int,vector<int>,less<int>>smaller;boollarger_not_full=true;// larger是个小顶堆,堆顶元素是最小的
// smaller是个大顶堆,堆顶元素是最大的
// 第K大数,表示有K - 1个数比他更大
// 有len - K个数比他更小
// e.g 4,5,8,2中的第三大数
// 有两个比他小,有一个比他大
// 我们以larger.top()为第K大数,则smaller里面始终保持len - K个元素
KthLargest(intk,vector<int>&nums){if(nums.size()==0)nums.push_back(-100000);// 放入一个极小值,对第K大数无影响
for(autot:nums){larger.push(t);}if(nums.size()>=k){for(inti=0;i<nums.size()-k;i++){smaller.push(larger.top());larger.pop();}larger_not_full=false;}// larger里的所有元素都大于堆顶
// 故保持larger个数为K个,即可从堆顶中获取第K大数
// cout << "Original " << k << "th. largest is " << larger.top() << endl;
}intadd(intval){intres;if(larger_not_full){larger.push(val);res=larger.top();larger_not_full=false;}else{if(val>=larger.top())// 比第K大数还大,第K大数可能改变
{smaller.push(larger.top());larger.pop();larger.push(val);// cout << larger.top() << endl;
res=larger.top();}else// 插入了一个更小的数,不会改变第K大数
{smaller.push(val);// cout << larger.top() << endl;
res=larger.top();}}returnres;}};/**
* Your KthLargest object will be instantiated and called as such:
* KthLargest* obj = new KthLargest(k, nums);
* int param_1 = obj->add(val);
*/
AC代码2
classKthLargest{public:priority_queue<int,vector<int>,greater<int>>larger;intK;KthLargest(intk,vector<int>&nums){K=k;for(autot:nums){larger.push(t);}while(larger.size()>k){larger.pop();}// larger里的所有元素都大于堆顶
// 故保持larger个数为K个,即可从堆顶中获取第K大数
// cout << "Original " << k << "th. largest is " << larger.top() << endl;
}intadd(intval){intres;if(larger.size()<K){larger.push(val);res=larger.top();}else{if(val>=larger.top())// 比第K大数还大,第K大数可能改变
{larger.push(val);larger.pop();res=larger.top();}else// 插入了一个更小的数,不会改变第K大数
{res=larger.top();}}returnres;}};/**
* Your KthLargest object will be instantiated and called as such:
* KthLargest* obj = new KthLargest(k, nums);
* int param_1 = obj->add(val);
*/