题目链接:https://leetcode-cn.com/problems/remove-duplicates-from-sorted-list-ii/
题目
存在一个按升序排列的链表,给你这个链表的头节点 head ,请你删除链表中所有存在数字重复情况的节点,只保留原始链表中 没有重复出现 的数字。
返回同样按升序排列的结果链表。
示例1
输入: head = [1,2,3,3,4,4,5]
输出: [1,2,5]
示例2
输入: head = [1,1,1,2,3]
输出: [2,3]
数据范围
- 链表中节点数目在范围
[0, 300]内-100 <= Node.val <= 100- 题目数据保证链表已经按升序排列
分析
在 有序 的链表中去重,表示我们理论上只需要进行一次遍历即可。
而两次遍历的办法则更为简单,也是最初浮现在我脑海中的念头。考虑到链表节点的数据范围在
[-100, 100]区间中,我们在第一次遍历的过程中记录每个数值出现的次数,而在第二次遍历过程中考虑下一个节点(的数值)是否应该存在于最终的结果中即可。
当然,两次遍历的办法随着节点数据范围的变大很快就失效了,投机不可取,一次遍历的办法如何实现呢?
在有序的数组中取得一段相同元素的子数组,直接考虑滑动窗口。
我们使用一个指针,指向窗口 左边界的左邻居 ,使用两个指针维护窗口的左右边界。当窗口右边界数值等于左边界数值时,窗口向右扩张,否则进行一定的更新操作。
容易想象,在不发生重复的情况下,窗口的大小(
right - left)始终为1,而发生重复的时候整段窗口需要全部从链表上删除。

窗口中无重复
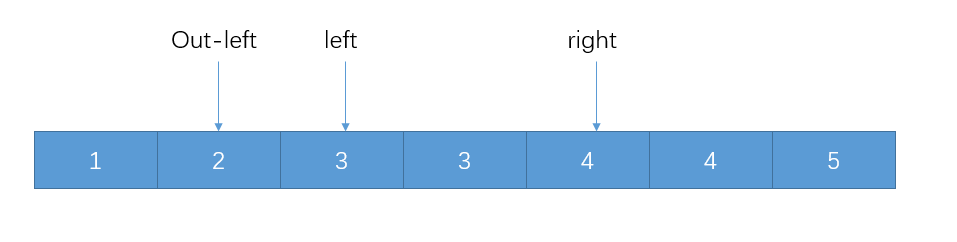
窗口中有重复 需要注意,由于我们的规则是:
right指针指向的元素与left指向的元素不同时,才停止窗口的扩张,进入更新操作,因此,right指针指向的元素并不属于窗口本身。那么如何更新呢?
我们注意到,当
right == left->next时,即winSize == 1时,不需要对窗口中的元素进行操作,则将三个指针往后移动,直接进入下一步的窗口更新环节即可。
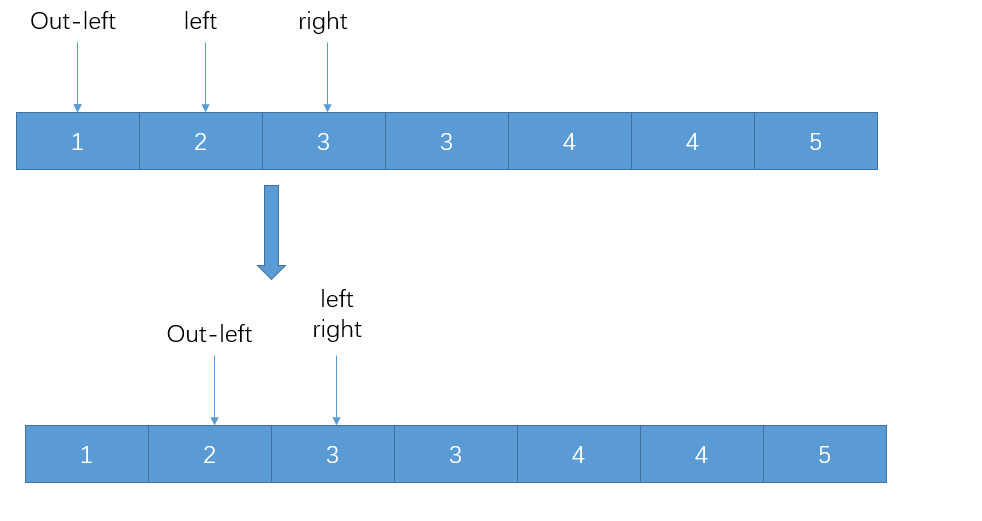
窗口大小为1时的更新办法 而窗口大小大于1时,就比较有趣了。我们直接将窗口 左边界的左邻居 ,即此处的
Out-left指向的元素链向right元素,这样就直接跳过了整个重复的部分,示意如下:
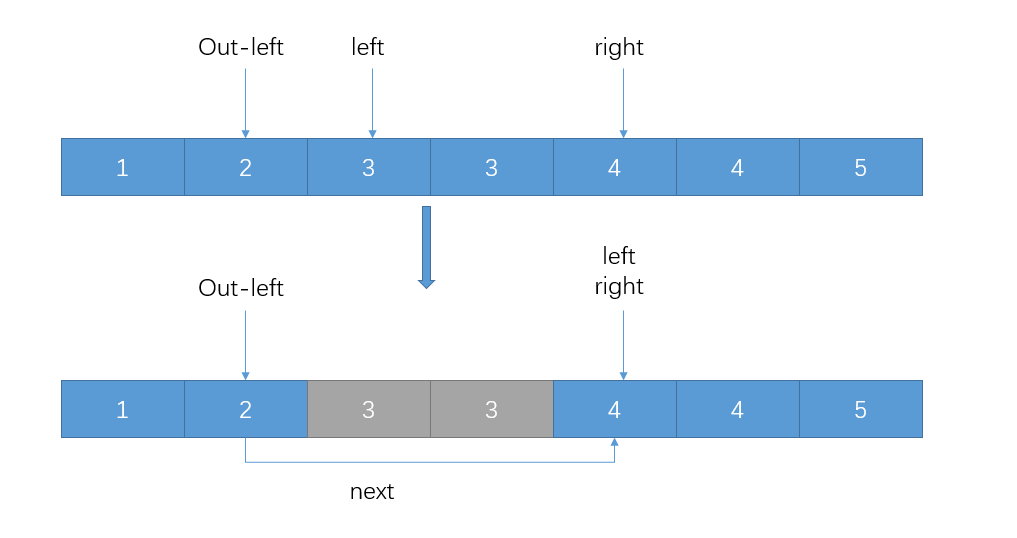
窗口大小不为1时的更新办法
到现在为止,我们已经完成了在正常情况下的遍历更新策略,但是循环遍历的边界条件很重要,且题目要求返回结果链表的头结点,这个头结点该如何确定也很重要。
首先是循环条件,我们使得
right指针指向最后一个节点时结束循环,因此while (right->next)。在我的首次提交中,使用了比较复杂的逻辑来判断头结点是否已经出现。当符合条件的头结点还没有出现时,对于当前的
right指针,当它的右邻居值与它不同,则说明当前这个right指向的节点是不用删除的,可以作为结果链表的头结点。同理进行
Out-left指针的判断。
AC代码1
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
if (!head || !head->next)
return head;
ListNode* lefleft = NULL;
ListNode* left = head;
ListNode* right = head;
ListNode* ret = NULL;
int winSize = 1;
while (right->next)
{
// cout << right->val << endl;
right = right->next;
if (right->val == left->val)
{
winSize++;
}
else
{
// cout << right->val << endl;
if (winSize != 1) // delete the window
{
// cout << "WinSize: " << winSize << endl;
if (!lefleft) // do not have previous node
{
if (!right->next || right->val != right->next->val)
{
ret = right;
lefleft = right;
}
}
else
{
lefleft->next = right;
}
left = right;
winSize = 1;
}
else
{
ret = (ret == NULL ? left : ret);
lefleft = left;
left = right;
}
}
}
// right points to the last node
if (winSize != 1) // delete the window
{
// cout << "WinSize: " << winSize << endl;
if (lefleft)
{
lefleft->next = NULL;
}
}
else
{
ret = (ret == NULL ? left : ret);
lefleft = left;
left = right;
}
return ret;
}
};
分析2
上面的代码显然由于引入了头结点的逻辑而变得非常臃肿,能否对其进行优化呢?
我们引入一个哑结点
dummy,它作为头结点之前的一个节点,初始化为dummy->next = head。此外,滑动窗口的思想实际上在此过于复杂,因为我们只需要判断窗口的大小是否为1,则只需要考虑
right是否等于left->next即可。于是一种较为简洁的思想诞生了:使用
pre、now、nxt三个指针来标识前一个节点、现在的节点和下一个节点。还是按照之前的办法对now(即之前的left)和nxt(即之前的right)进行更新。由于pre被初始化为dummy节点,故一轮遍历之后,dummy->next所指向的节点一定是第一次符合条件的节点,为返回的链表头部。
AC代码2
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
if (!head || !head->next)
return head;
ListNode* dummy = new ListNode(0);
dummy->next = head;
ListNode* pre = dummy;
ListNode* now = head;
ListNode* nxt = head->next;
while (nxt)
{
if (nxt->val == now->val)
{
nxt = nxt->next;
}
else
{
if (nxt == now->next)
{
pre = now;
now = nxt;
nxt = nxt->next;
}
else
{
pre->next = nxt;
now = nxt;
nxt = nxt->next;
}
}
}
// 注意此处细节,循环结束之后进行最后一次判断
if (nxt != now->next)
{
pre->next = NULL;
}
return dummy->next;
}
};
参考资料
[1] 力扣官方题解.删除排序链表中的重复元素 II[EB/OL].2021-03-24