题目链接:https://leetcode-cn.com/problems/subsets-ii/
题目
给你一个整数数组 nums ,其中可能包含重复元素,请你返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。返回的解集中,子集可以按 任意顺序 排列。
示例1
-
输入: nums = [1,2,2]
-
输出: [[],[1],[1,2],[1,2,2],[2],[2,2]]
示例2
-
输入: nums = [0]
-
输出: [[],[0]]
分析
三个月之前WA过的题,在每日一题里碰见了,而我还是思考了很久 😢
原始数组中可能包含重复元素,则对于重复元素的考虑就尤为重要,一般来说,重复元素对于子集的贡献也有重复。
我们不妨考虑进行以下的模拟,对于一个 不包含重复元素 的集合
[1, 2, 3],如何求得它的所有子集呢?首先,答案中包含一个空集。
首先取得第一个元素,将其与当前答案中的所有集合拼接,放入答案中;
考虑第二个元素,将其与当前答案中的所有集合拼接,放入答案中;
第三个元素同理。
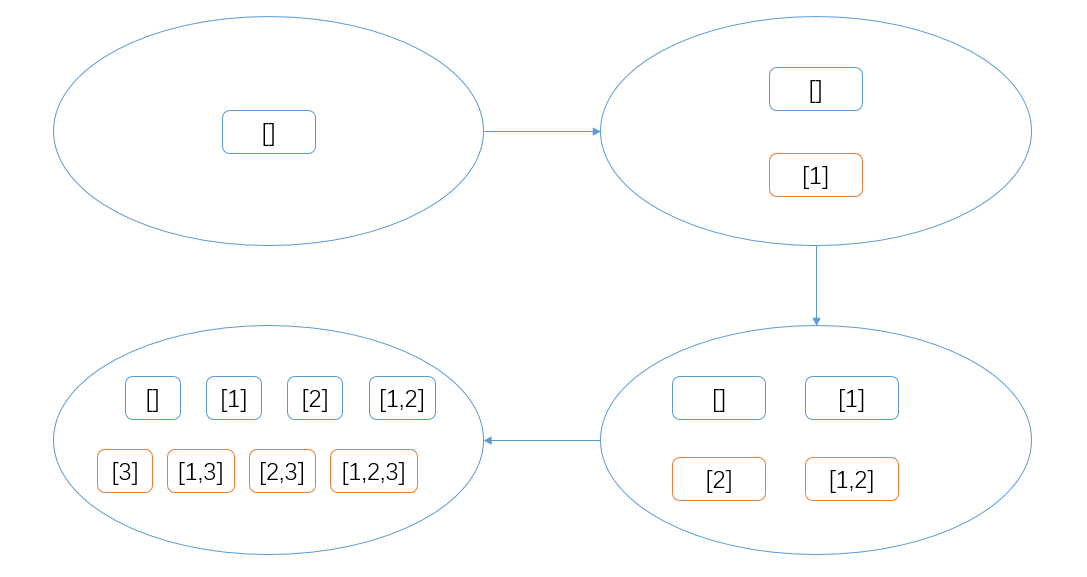
示意 在这个环节中,由于答案是在不断地增长的,我们只需要用一个变量保存添加元素之前的答案集合大小即可。
这种做法的正确性是
不会证明理所当然的。实际上,根据这种做法我们可以AC掉 LeetCode78. 子集 。
// LeetCode 78 class Solution { public: vector<vector<int>> subsets(vector<int>& nums) { vector<int> tmp; vector<vector<int>> res; res.push_back(tmp); // empty set for (auto n : nums) { int sze = res.size(); for (int i = 0; i < sze; i++) { tmp = res[i]; tmp.push_back(n); res.push_back(tmp); } } return res; } };
那么问题在于,本题的原始数组是可以重复的。
对于重复数据,首先可以进行一波排序,使得我们比较方便地进行判重。
在上面的做法中,重复数据产生的答案会有相当一部分重复,我们考虑集合
[1, 2, 2]:
![对集合[1,2,2]进行同样的操作](/p/%E9%9A%BE%E9%A2%98%E6%9C%AC-leetcode90.-%E5%AD%90%E9%9B%86-ii/2.png)
对集合[1,2,2]进行同样的操作 可以看到,对于重复出现的
2来说,它不需要再与[]和[1]进行合并。那么,重复数据在哪里能够产生贡献呢?
答案就是 上一步新加入的子集 !
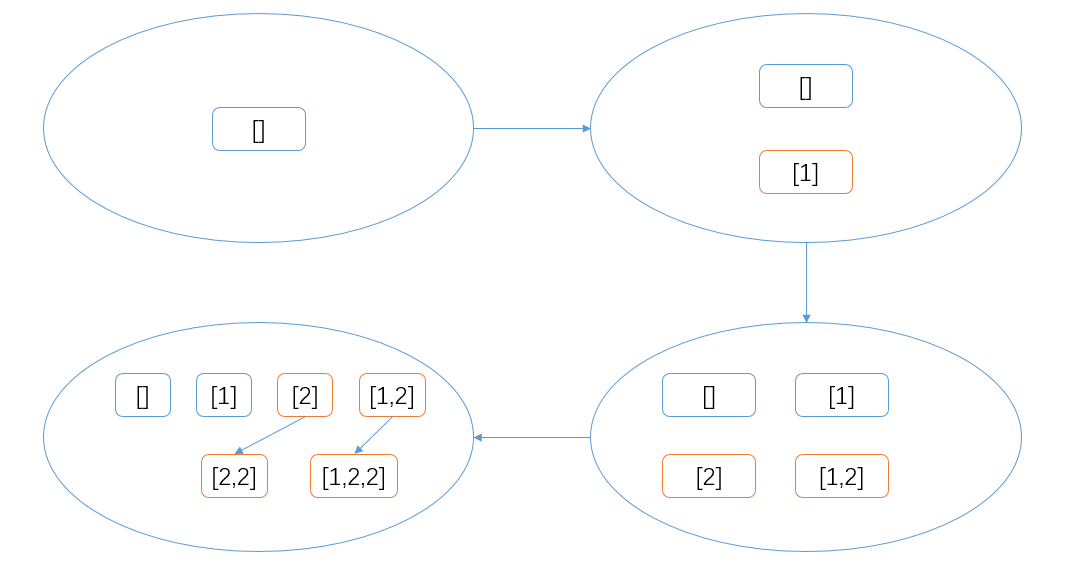
重复数据与上一步加入的子集合并 由此,形势就变得比较明朗了。对于非重复的数据,与目前拥有的所有子集进行合并;对于重复的数据,只与上一步加入的子集进行合并。
如何只获取上一步加入的子集呢?在上面给出的代码中,我们使用
sze来记录答案集合中原本的大小。很巧的,上一步加入的子集在答案集合中的下标就从sze开始。于是,使用一个变量
start来记录本轮需要合并的子集起点,当当前的数是重复的,start就被设置为sze,然后更新新的sze,否则start直接设置为0。
AC代码
class Solution {
public:
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
vector<vector<int>> res;
vector<int> tmp;
res.push_back(tmp);
int start, sze;
sort(nums.begin(), nums.end());
for (int idx = 0; idx < nums.size(); idx++)
{
if (idx > 0 && nums[idx] == nums[idx - 1])
{
start = sze;
}
else
{
start = 0;
}
sze = res.size();
for (int i = start; i < sze; i++)
{
tmp = res[i];
tmp.push_back(nums[idx]);
res.push_back(tmp);
}
}
return res;
}
};
小结
三个月前WA掉的题目在今天重新来到我的面前,经过一番思索之后能够独立地将其做出来了。人生点滴进步大抵皆见于此类细节之中。题解基本采用回溯的办法,在此没有花费精力予以研究。亦因此本文无所参考,便有,也是此三月中所见的某篇文章,回忆不清矣。