今年的cppcon相当有趣,有好几个选题看上去对我的工作颇有启发,后面应该会慢慢看完。
今天看的演讲是Daisy Hollman带来的《Crafting the Code You Don’t Write: Sculpting Software in an AI World》,她作为Anthropic(Claude编程模型的母公司)的一员,分享了关于软件工程师如何在AI时代跟上潮流、不断进步的方法。
1 理解LLM
1.1 Transformers & 早期预训练模型(2017、2018)
这部分在公司看的,不做细致记录了~(懒)。
大致就是介绍了一下模型注意力机制的由来以及早起的预训练模型(类似深度学习这样的训练-预测的玩法)。
1.2 Scale 力大砖飞(2019~2020)
LLM第二阶段,Daisy称之为取得了 unreasonable effectiveness of scale ,在我看来它是一个力大砖飞的阶段。
以往的模型有点类似于训练数据的压缩包,训练的过程就是把训练数据“压缩”到模型中,而测试或使用的过程就是要求模型把训练数据“解压”出来,通过概率的方式表达。随着训练规模的增长,产生了一些概念泛化( conceptual generalization )的效果,由原本的训练集的复读机变成看上去稍微有点思想的东西。

Daisy以一个返回值填充的案例来说明大模型在什么地方取得了概念泛化。首先是人类的思维模型:

这里的答案其实是 widget ,这是自C++11就有的返回值自动移动机制,Daisy在后文称为隐式移动( implicit move )。
拓展阅读
https://en.cppreference.com/w/cpp/language/return.html#Notes
接下来Daisy做了很有趣的分享,把这段程序喂给模型,模型的输出是什么?
unique_ptr<Widget> widget_factory() {
using namespace std;
unique_ptr<Widget> var = make_unique<Widget>();
var->initialize();
return 🤔🤔🤔
}
注、这段程序有几个点是经过设计的:
- 变量名改为
var,这样模型就不会产生关于Widget的倾向using namespace std;,使得模型更关注返回值是否使用move而非命名空间
模型的输出概率分布:
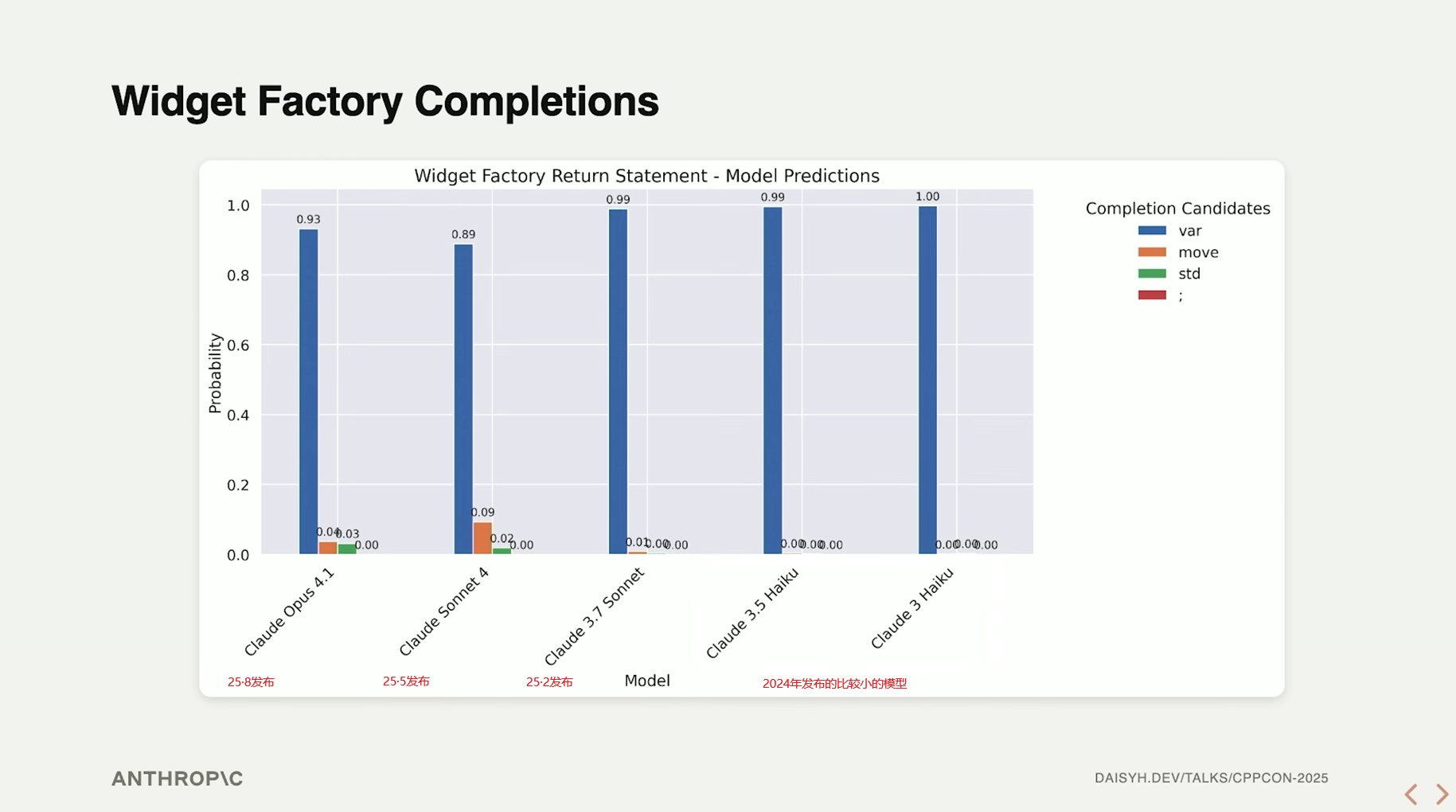
这里有个有意思的点是:较老的模型反而坚定地输出 var ,而较新的模型则在保证答案正确的情况下,有一定的概率输出 move(var) 。Daisy和她的同事经过了调研,最终给出的解释是 老模型纯粹地认为这段代码是Python (绷🤣);而新的模型已经泛化出了移动语义的概念,只是有小部分时间会遗忘隐式移动的存在,输出显式的 move 。
对于能够理解 移动 语义而只是单纯忘记有隐式移动这么一回事的模型,只要一个简单的trick就可以证明:
unique_ptr<Widget> widget_factory() {
using namespace std;
unique_ptr<Widget> var = make_unique<Widget>();
var->initialize();
// Implicit move
return 🤔🤔🤔
}
在返回值之前添加了隐式移动的注释后,真正理解这个概念的较新的模型,得到了正确的输出:
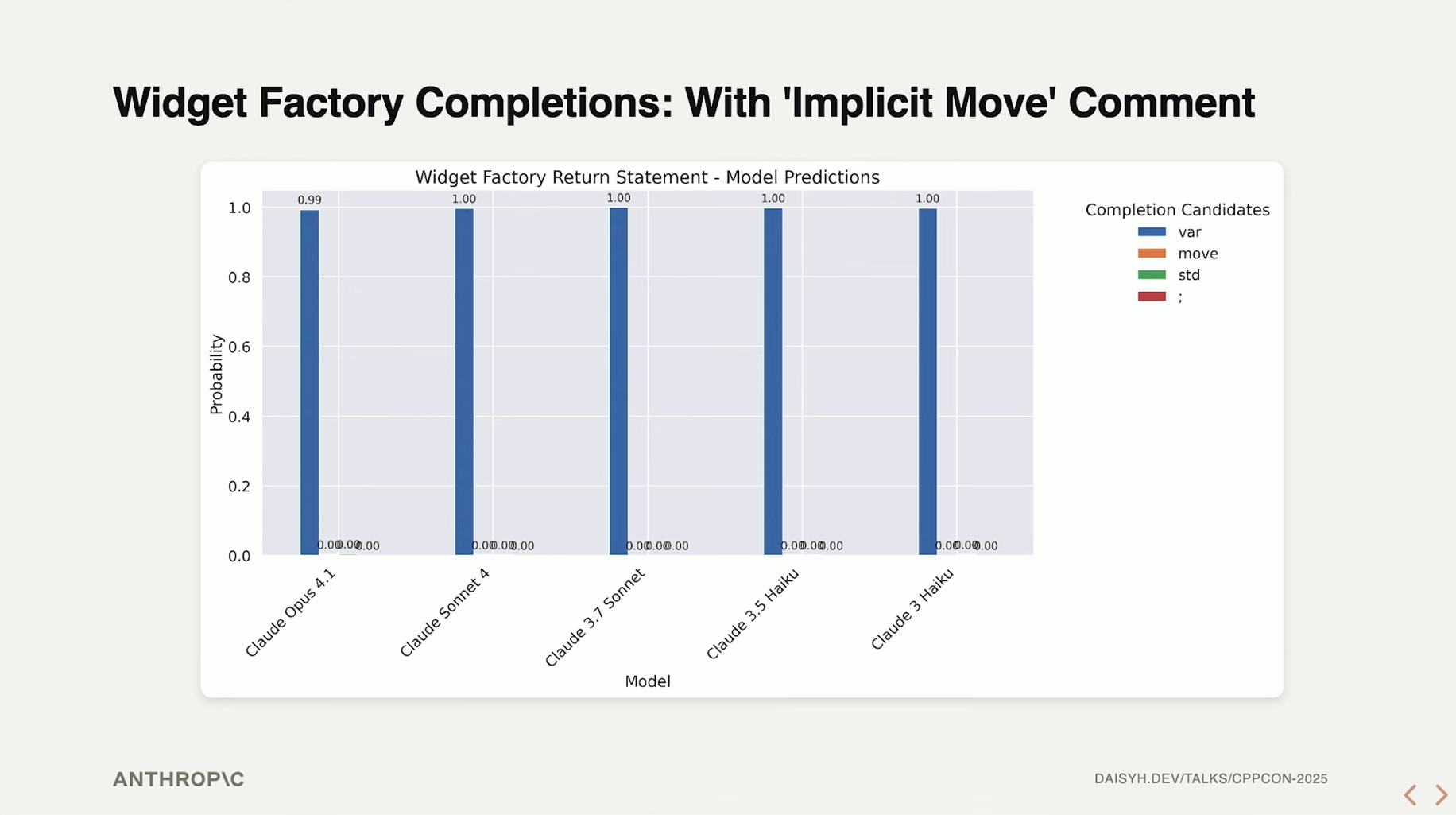
Daisy从反方向构造了新的考验:如果模型真的理解什么是隐式移动,那么告诉模型当前 不能 使用隐式移动的话,能够得到正确的输出吗?
unique_ptr<Widget> widget_factory() {
using namespace std;
unique_ptr<Widget> var = make_unique<Widget>();
var->initialize();
// remember that implicit move is broken in our compiler
return 🤔🤔🤔
}
模型输出概率分布:
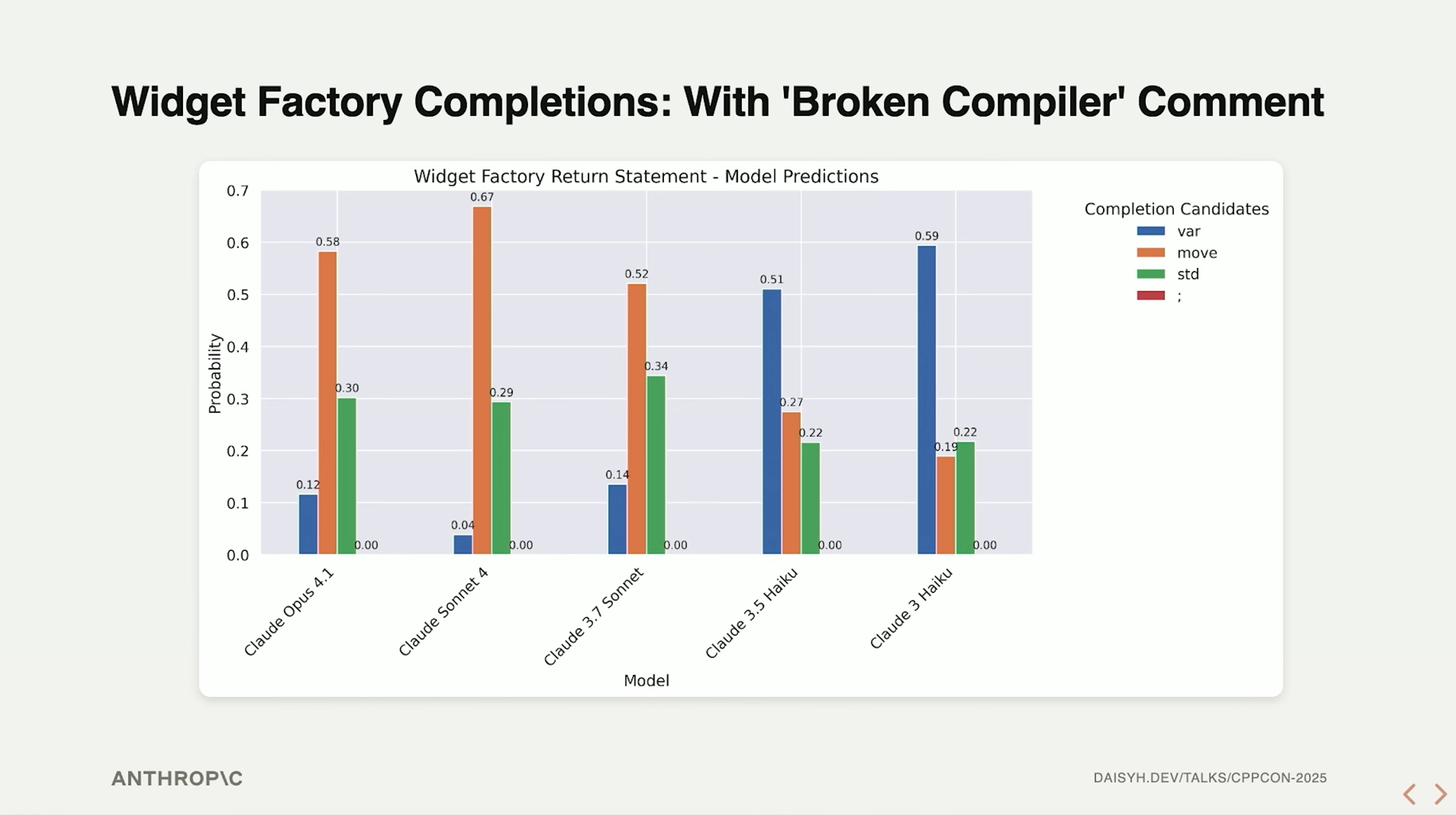
总而言之,这一节的关键在于提出了“数据压缩”、“概念泛化”这样的概念。阐明了随着模型规模的增长,模型的知识存储与输出的方式达到了更高的层次。

1.3 强化学习(2022)
这一章介绍得比较简略,主要是讲了一些强化学习的核心思路。
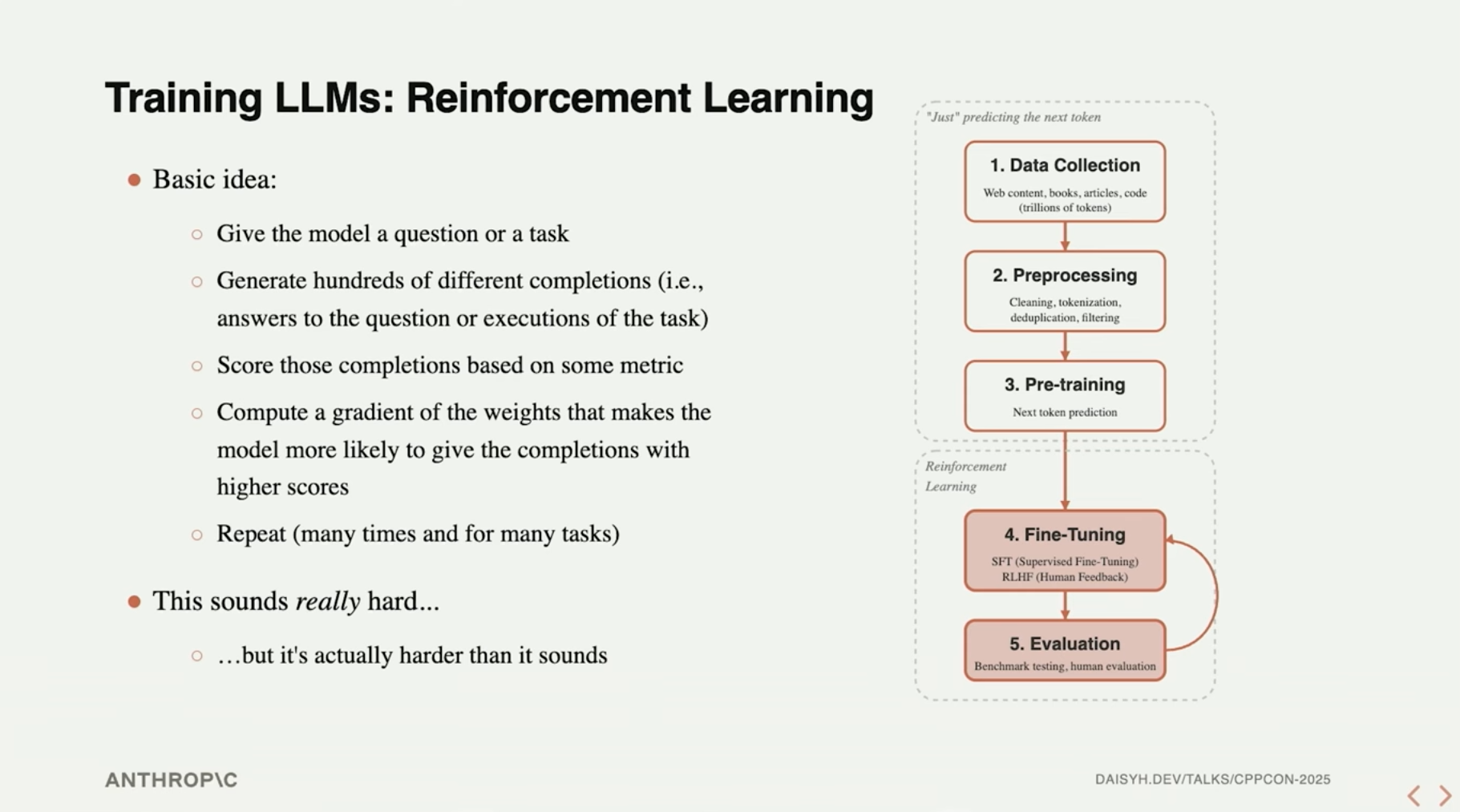
强化学习的核心概念还是比较容易理解,跟我们教育小朋友是类似的,当小朋友做出了错误行为时,会受到惩罚,而当小朋友做出正确的行为时,会获得奖励,以此引导小朋友做出正确的行为。对于LLM,当模型产生了不符合预期的输出时,会受到惩罚(调整权重使得模型下次更少地产生这种输出),而当模型产生符合预期的输出时,会获得奖励(调整权重使得模型下次更多地产生这种输出),以此逐渐使得模型的输出符合人们预设的偏好。
拓展阅读
1.4 工具使用(2023~2024)
人们意识到,类似于XML/JSON等含有特殊语法的标记语言,本质上仍是一些文本内容,不妨为大模型定义一些特定的 schema (非AI领域,不确定这个词中文术语是啥),当模型的输出过程中产生了符合 schema 的内容时,可以视为一次工具调用。
Daisy演示了当前Claude code是如何完成文本编辑的:

Daisy这里给出了一个比喻,这样进行工具调用简直是处于 ed 时代,尚未发明 vi 。简单看了下 ed 是个啥,的确有点原始,Daisy想表达的意思也可见一斑了。
拓展阅读
1.5 推理(Late 2024)
模型的上下文窗口在过去的时间里取得了长足的增长,对数图:
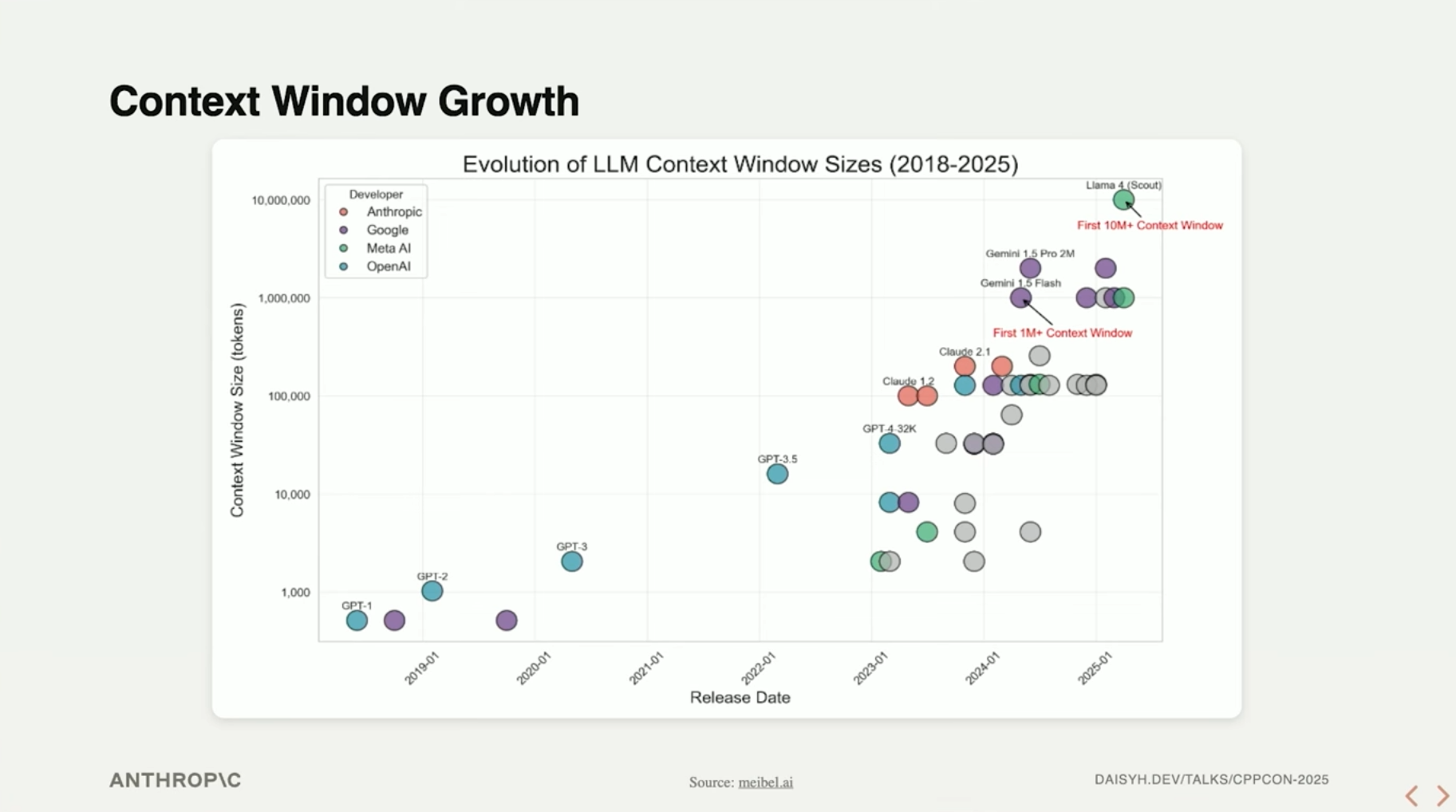
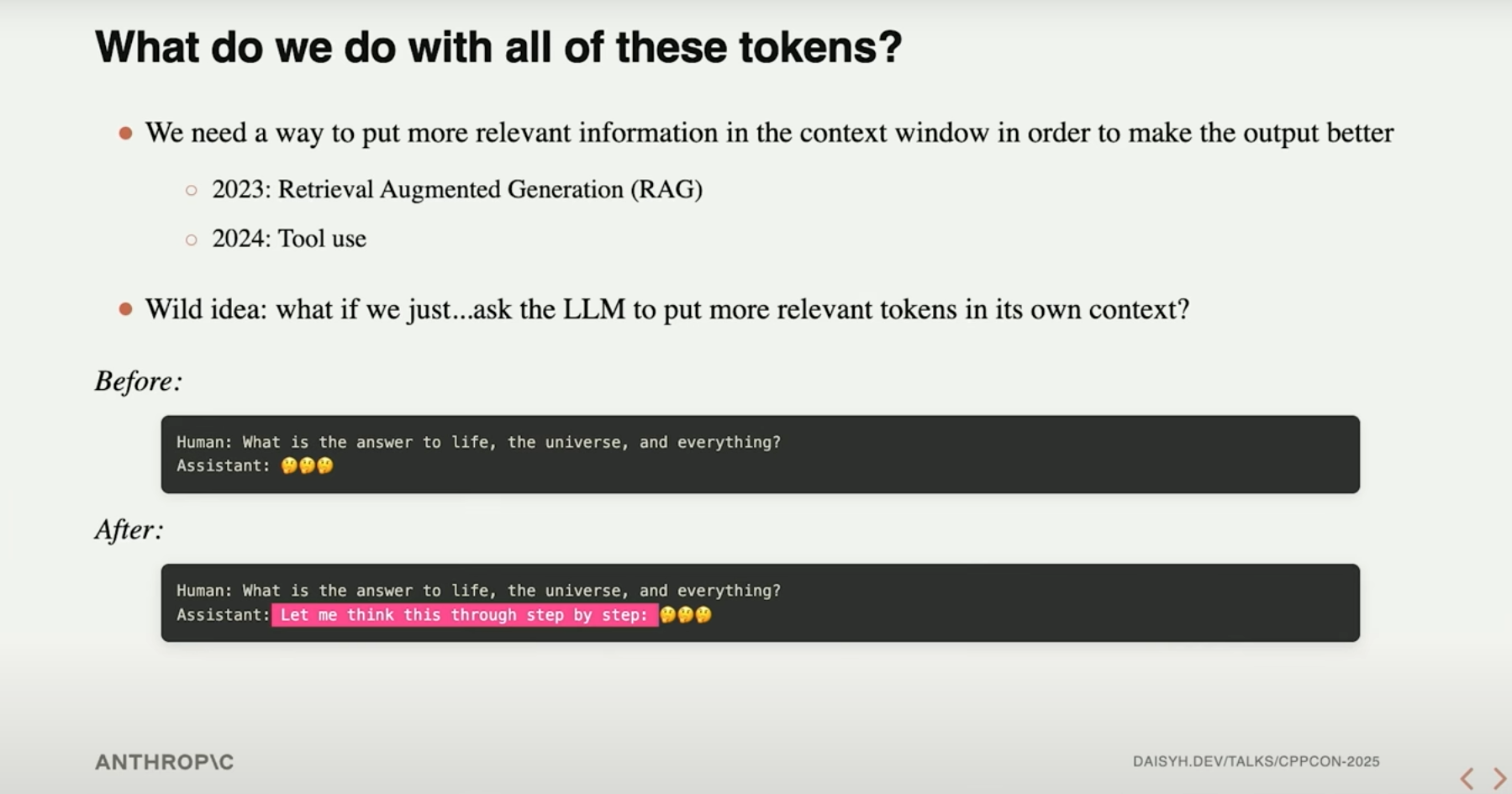
人类对于如何使用这么大的上下文窗口,经历了一定的返璞归真的创新,由RAG(信息检索增强)、工具调用,逐步走到了让模型自行进行推理。
1.6 Agent(2025)
随着上下文窗口的扩展,模型能够对当前任务所发生过的历史情形有更多的了解,并能够自行分析自己上一步行为的结果并进行迭代优化。

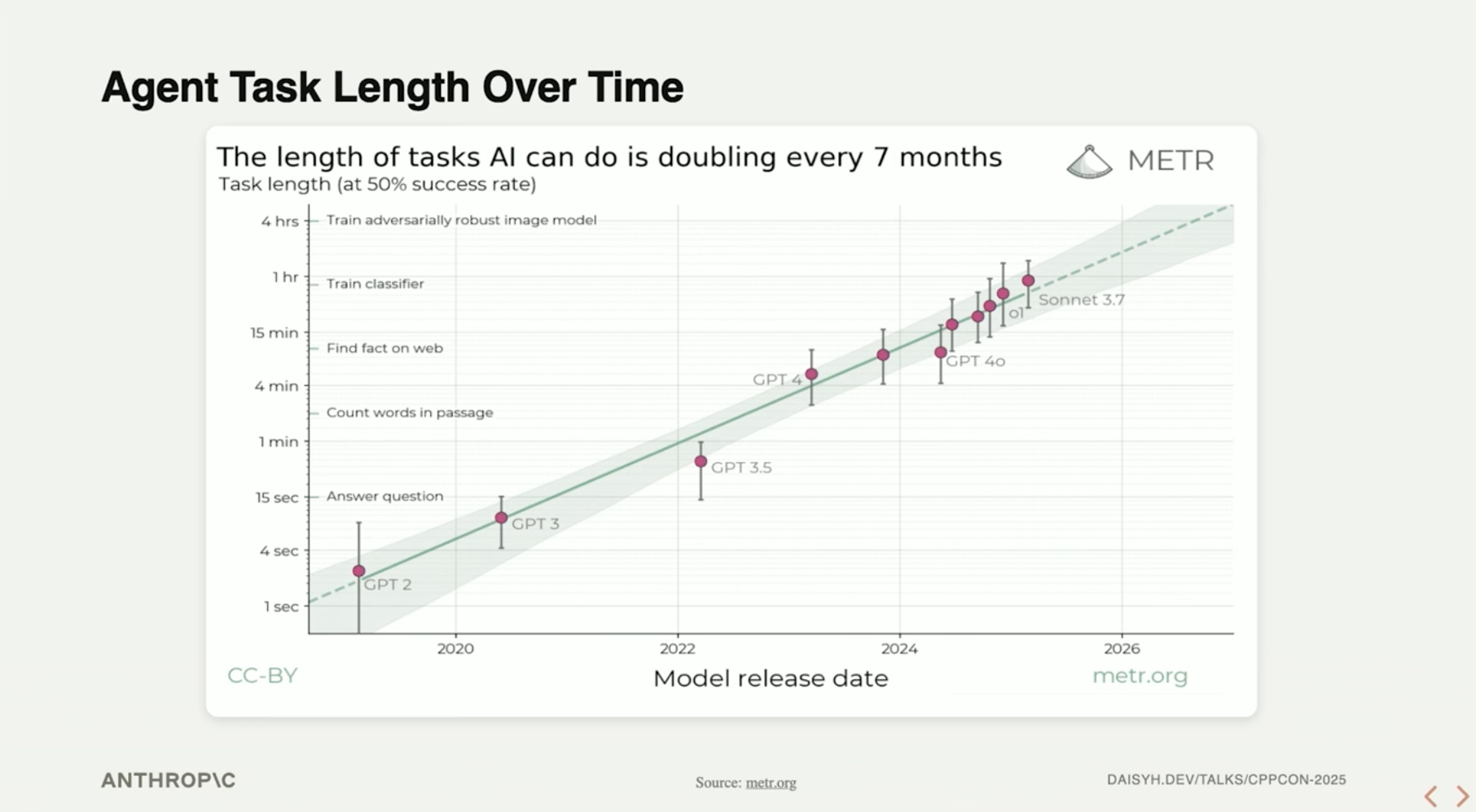
这种模式在编码领域的应用,就是Coding Agent。
不妨考虑人类在参与一个巨大工程时的行为:
-
找到我们需要维护的功能的关键入口
-
找到这个入口函数的调用点、参数等
-
对于其它的功能,我们只是了解一些大概
在巨大上下文窗口的加持下,这样的模式完全能够由Agent实现。
2 Coding with LLM
这一部分的开始,Daisy解释了她是如何看待一个Coding Agent的,和我个人的实际体感不谋而合:

AI在抽象设计、需要平衡多方利益的功能库开发等场合,表现并不好,而在系统构建、模板元编程等方面可能表现优异(得益于丰富的训练数据)。
一些适于运用Agent的方向,一定程度上也拓展了我的思路:
- 快速原型构建
- 辅助编程——核心逻辑人工开发,分支逻辑交给AI
- 规划和头脑风暴
- 学习和调研
- 重构
- 测试用例生成
最佳实践:清晰明白的代码
不要让模型“猜”我们的接口或函数。当我们开发代码时,保持“最小困惑”原则,思考我们的代码可能被以哪些方式 误解 ,以最 直白 的方式来表达一件事情。
避开一些可能令模型惊讶(实际上,同时也令人惊讶)的c++写法:
- 避免自作聪明地重载运算符
- 避免在同一个类型中混合使用拥有和非拥有语义
- 避免使用宏
- 避免使用参数依赖查找(ADL)
- 避免隐式转换
- 尽量使用基础类型
拓展阅读
最佳实践:封装优先
🔹1. Create, maintain, and document rigorous invariants at encapsulation boundaries
-
创建、维护并记录封装边界上的严格不变量(invariants)
-
不变量(invariant) 是指对象在生命周期中必须始终成立的条件。例如:一个表示“非负数”的类,其内部值永远不能为负。
-
封装边界 指的是类或模块的接口(public API),外部代码只能通过这些接口与内部逻辑交互。
-
✅ 建议:在接口处明确声明和保护这些不变量,确保即使外部调用错误也不会破坏内部状态。这有助于提高代码的健壮性和可预测性。
🔹 2. The agent should be able to reason about the code in isolation as much as possible
代理(agent)应尽可能独立地推理代码行为
要求:代码模块的设计应足够清晰,使得 AI 或其他自动化工具无需了解全局上下文就能理解其功能和约束。
✅ 实现方式:
- 使用清晰的命名
- 提供完整的文档注释
- 避免隐式依赖
- 👉 这样可以提升代码的可读性、可测试性和可维护性。
🔹 3. Avoid code coupling!
避免代码耦合!
耦合(coupling) 指不同模块之间的依赖程度。高耦合意味着修改一个模块会影响多个其他模块。
- ❌ 不推荐做法:为了复用代码而在完全不同场景中共享同一段实现,从而破坏封装。
- ✅ 推荐做法:宁愿重复代码(DRY 原则的适度放松),也不要强行将不相关的逻辑绑定在一起。
- 📌 特别强调:“Err on the side of repeating yourself rather than breaking encapsulation by reusing code in vastly different scenarios” 👉 即:宁可重复,也不破坏封装。
这体现了现代 C++ 设计哲学中的一个重要思想:封装优于复用,尤其是在面对复杂系统时。
最佳实践:代码文档化
🔹 1. Comments are more important for agents than they are for humans!
注释对 AI 代理比对人类更重要!高质量的注释是 AI 理解你意图的关键输入。
🔹 2. Frequent, verbose comments in code can act like extended thinking
频繁且详尽的注释可以作为“扩展思维”的体现
注释不仅仅是解释“做什么”,还可以表达“为什么这么做”、“有哪些限制”、“未来可能如何演变”等。
对于 AI 来说,这种额外的信息相当于提供了上下文推理能力,有助于它做出更合理的决策。
📌 类比:就像你在写论文时加入大量思考过程,AI 可以从中学习你的设计逻辑。
🔹 3. Unlike previous advice: redundancy is useful!
与以往建议相反:冗余是有用的!
传统编程原则提倡“不要重复自己”(DRY),但这里指出,在注释中适度重复是可以接受甚至有益的。
例如:
-
在函数头部写清楚参数含义
-
在关键逻辑处再次说明其目的。即使某些信息可以从代码推断出来,也应显式写出
👉 目的是让 AI 更容易捕捉到关键信息,避免因上下文缺失而误解。
🔹 4. Think about the things that you can’t say with your code and put them in comments
思考那些无法用代码表达的内容,并将其写入注释
代码只能表达“怎么做”,但不能直接表达:
- 设计假设(assumptions)
- 性能权衡(trade-offs)
- 业务规则(business logic) “对于所有情况”的契约(“For all” contracts)
📌 示例:
// This function assumes that input is always valid due to upstream validation.
// It does not handle malformed data because it's guaranteed by contract.
🔹 5. Agents are very good at generating and maintaining comments
AI Agent非常擅长生成和维护注释。当前 AI 工具已经能够根据代码自动生成文档、添加注释、更新过时内容。
✅ 建议:利用这一能力,将注释维护自动化。
💡 具体建议:Add a CI step that asks an agent to verify all of the comments related to changes in your pull request!
在持续集成(CI)流程中加入一个步骤,由 AI 检查 PR 中修改的代码是否附带了足够清晰、准确的注释。如果注释缺失或不一致,自动标记问题,提醒开发者补充。
小结
最佳实践本身并不区分代码是写给AI看还是写给人看,本质上只是要求我们写出来的代码更 易懂 。在AI时代,你的代码是否真正易懂,可以侧面体现在模型是否快速理解了这段代码的意图,并正确地维护起这段代码。

3 面向AI的编程语言演变
这一章,Daisy提出了面向AI的c++语言进化方向,使得这门语言在将来更易于与AI编程结合。
函数调用的“Two-sided Naming”
由于这个词是Daisy发明的,不特地翻译。简单来说,就是认为在函数调用点处对参数信息提供更多的声明。

这个特性对人类来说可能无关痛痒,毕竟目前在各种IDE中基本都有类似的插件可以索引到一个函数的声明(无需跳转到头文件);不过面向AI,的确是一个挺关键的思路:如果cpp本身带有一个函数的参数信息,AI就可以不再需要自行检索头文件,而这恰好是非常考验AI能力的一步。
契约和影响描述

这部分基本属于大佬的YY,也许是一个注释就能搞定的事情?
没有太get到这个倡议的点,简单让千问帮我梳理了下:
✅ 总结: 这张幻灯片的核心观点是:
在未来由 AI 协助开发的世界中,良好的封装不仅是软件工程的最佳实践,更是提升 AI 理解能力的关键。
而 契约 和 效果系统 正是实现这一目标的强大工具:
| 特性 | 作用 |
|---|---|
| 契约 | 提供行为规范,支持泛化推理(如 Liskov 替换) |
| 效果系统 | 明确副作用,支持局部推理和安全性分析 |
这标志着编程语言设计正在从“面向机器执行”转向“面向人类与 AI 共同理解”。
观感上可能和最佳实践里的“封装”和“文档化”差不多吧。
4 总结
最后贴上Daisy的总结:

其中有几个很有意思的点,写一点感悟。
-
“LLM做不到这点” –> “我不能用LLM做到这点” 。的确,LLM的能力就在那里,有谁能说自己已经摸到了LLM的上限呢?世界上依托大模型快速构建出来的软件甚至公司都有不少,作为比较基层的开发人员,用得好,用不好,目前更多的还是个人而非LLM的能力问题,将对LLM的使用作为一项技能而不断磨练精进,可能是更妥当的思路。
-
AI和代码的互相驱动。以往我们总是关注AI如何实现我们的需求,而忽视了我们的代码本身如何使得AI更好或不好地实现我们的需求。AI理解不了我们的项目——这完全是AI的问题吗?我们的代码是否做到了简洁、架构是否做到了清晰?相比于苦苦探索如何通过冗长的思维链、繁琐的工作流、精巧的提示词来使AI理解项目代码,另一条更优雅的路径可能埋藏在代码本身之中。蓦然回首,那人却在灯火阑珊处。
5 Q&A
Q&A环节,一些问题也颇有启发,浅做记录(记录我理解到的意思而非忠实地翻译问答对话)。
Q:在一个较大的团队中,如何在使用Agent的过程中避免上下文混乱,类似于多方会谈中,如何清晰地交接任务?
A:一种方向是Agent的记忆( memory ),建议大家关注这个话题。
Q:如何处理上文(该演讲)中提到的不确定性所带来的安全问题?
A:自己编写关键代码。在公司中有一部分文件,是绝大多数人不允许用Claude编写的。这是我们的实践。
Q:(提到关于最佳实践中注释的部分)注释通常是静态的,而代码是动态演进的。AI在自动(基于最新代码)维护注释这方面表现有多好?
A:我们定期运行这个步骤(指AI自动维护注释)并审查AI的输出,效果非常好。实际上我们的CI已经基本解决了注释腐化的问题。我们确信这是Agent非常擅长的任务。
Coooool,一种不错的思路